I think it is important to note that the information I gleaned from my MALLET data cannot be the only method of research pertaining to the focus of eugenic writing in the 19th and 20th centuries. Text mining is limited in the fact that the programs do not look at the meaning of the words only the statistical significance (or how many times it appears in a document). Therefore it is very hard to ascertain the context without going back to the original document. That is why my recommendation to any individual thinking of using text mining would be to use topic modeling to get ideas about the larger picture and then to go back to the original sources (or at least a few of the interesting ones) to add and provide context to your project.
Learning text mining for this digital project has been both a great struggle and a great accomplishment. My results were limited to the small corpus I had, and by my ability to use the text mining tools of MALLET and Word Clouds. Despite these limitations, I still was able to use text mining to conclude that heredity and family were amongst the largest factors in writing involving eugenics in the nineteenth and twentieth centuries. I also ended up finding more questions than I expected, such as why 1912 was so significant and why the topic of war had no publications in 1917 and 1918. These are questions that I would like to explore further in future projects. While I ended up with more questions than conclusions, I was able to really immerse myself in one method of digital analysis and see a small glimpse of the style of research that some digital historians use.
Bibliography
Ellis, Havelock. “Eugenics Made Plain”. Internet Archive, 1920. https://archive.org/details/eugenicsmadeplai189elli.
Heron, David. “The Influence Of Defective Physique And Unfavourable Home Environment On The Intelligence Of School Children”. Internet Archive, 1910. https://archive.org/details/influenceofdefec00hero.
Starkweather, George Briggs. “The Law Of Sex : Being An Exposition Of The Natural Law By Which The Sex Of Offspring Is Controlled In Man And The Lower Animals, And Giving The Solution Of Various Social Problems”. Internet Archive, 1883. https://archive.org/details/lawofsexbeingexp00staruoft.
Walker, Alexander. “Intermarriage: Or, The Mode In Which, And The Causes Why Beauty, Health, And Intellect, Result From Certain Unions, And Deformity, Disease, And Insanity, From Others”. Internet Archive, 1839. https://archive.org/details/intermarriageor00walkgoog.
The first tool that I used to analyze my results was Word Clouds. Unfortunately, I was unable to figure out how to download multiple documents at a time for the website to analyze. So instead of looking at the entire corpus, I chose a few select sources to demonstrate how visualizations like Word Clouds could be used to analyze what was being written in relation to eugenics.
Image 1 depicts a Word Cloud created using the source “Intermarriage or the Mode in which, and the Causes of Why Beauty, Health, and Intellect Result from Certain Unions and Deformity, Disease and Insanity from Others.”[1] What is particularly intriguing about this particular source is that when you read the book and see some of the most prominent terms in the Word Cloud, such as ‘organs,’ ‘women,’ ‘breeding’ and ‘development’, the connection to eugenics is quite clear. And yet this source was published in 1839. That begs the question as to whether the study of eugenics really started in 1883 when Francis Galton coined the term or if it actually emerged earlier in some groups. This source is also almost entirely focused on women and female issues, which suggests that at this time ideas that would soon become known as eugenics were still focused on explaining how the female body operated.
Image 1: “Intermarriage or the Mode in which, and the Causes of Why Beauty, Health, and Intellect Result from Certain Unions and Deformity, Disease, and Insanity from Others.”
I also chose to look at the source “Eugenics Made Plain” written in 1920 due to the fact that it was written by a very influential eugenicist Havelock Ellis.[2] Image two very much represents the title of Ellis’ book and the study of eugenics as a whole. The terms ‘life,’ ‘race,’ ‘social,’ ‘disease,’ and ‘defective’ are issues that were commonly associated with eugenics. The social aspects of society were impacted by the factors of race, disease, and the defective. This source is also less focused solely on women, which suggests that men, women, and society as a whole had now adopted the ideas surrounding eugenics.
Image 2: “Eugenics Made Plain”
In addition to the simple use of word clouds, I also used the MALLET data as another tool of analysis. While text mining is a very useful tool for a historian or humanist seeking to examine hundreds or even thousands of documents in a very short period of time, the results generated by MALLET require human interpretation and further analysis. Taking the MALLET data that I created, I first decided to look at how many sources were published per year during my time period.
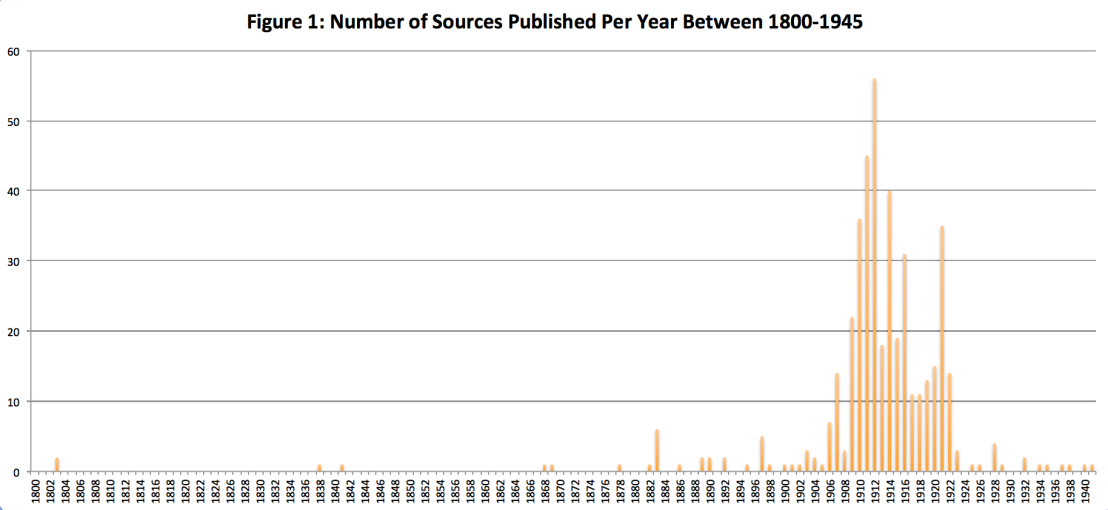
Figure 1 visualizes the number of sources per year that were published about eugenics, which gave some very predictable results and some unexpected results. As one would expect when looking at the study of eugenics, the chart shows that 1883 was the year that sources about eugenics really started to emerge, which is unsurprising given the fact that that was the year that Francis Galton coined the term. Also unsurprising is the fact that sources about eugenics were most popular from the turn of the century into the interwar period and then began to decline as we get closer to the Second World War. The decline in the number of sources correlates with the decline in the use of the word “eugenics” as the term became associated with the Nazi atrocities of the Second World War.[3]
What was surprising about this chart was the number of sources that were published prior to Francis Galton establishing eugenics as a field of study. The first two sources included in my corpus were published in 1803, nearly 80 years before eugenics was even a term. However, they are in French (despite my search request for only English sources) so all I was able to surmise is that perhaps eugenics in non-English speaking countries emerged earlier. However, there were six other sources that were published in English prior to 1883. Published between 1838 and 1882, these sources were included in my search on ‘eugenics’ because they were written about intermarriage, race degeneration, population, heredity, and insanity, all of which would become topics that were related to the eugenics movement.
Figure 1
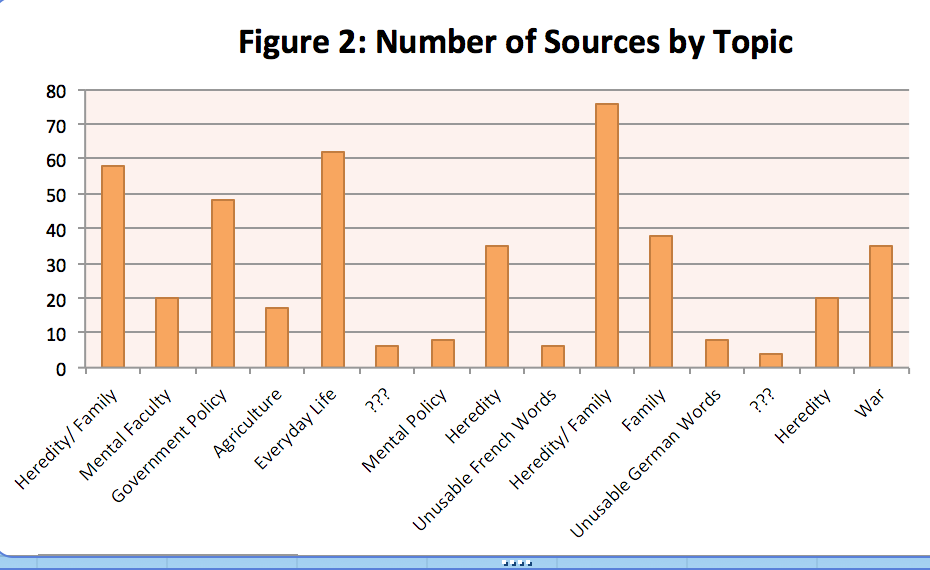
Figure 2 also looks at the number of sources in the entire corpus but this time the chart displays the breakdown of sources by topic. The number of sources per category was determined using the topic label that each source listed as their highest proportion. The importance of heredity and family was reinforced by this data given that topic 9 on Heredity/Family had the highest number of sources. What was really surprising though was topic 1 (Mental Faculty) and topic 6 (Mental Policy). Societies during this time were very clearly concerned with how heredity impacted not only families but also society as a whole. So I was shocked that there were so few sources related to mental faculty and policy when the ‘solution’ that was often offered to those considered to be unfit commonly involved being placed in a mental institution or being sterilized to keep the ‘evil’ from spreading further in society.[4]
Figure 2
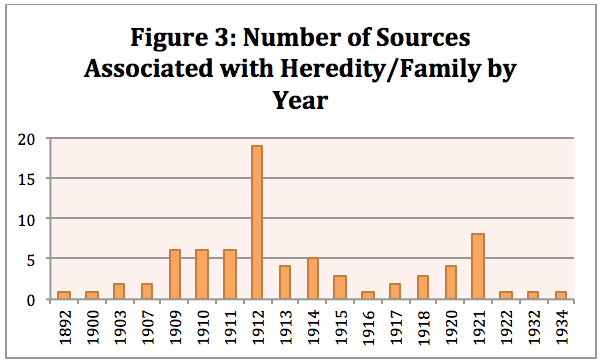
After looking at all of the sources by year, I narrowed my search to look at the sources by year for specific topics beginning with topic 9. Figure 3 displays the number of sources by year that had topic 9 as their highest proportion. From this figure we can see that 1912 was a particularly significant publication year for sources related to heredity and family, having published 19 sources. All of the other years seem to be relatively similar in the number of publications with the exception of 1921, which also experienced a spike but a much smaller one. The spike in 1912 begs the question as to why 1912 had double or even triple the number of publications in comparison to other years.
Figure 3
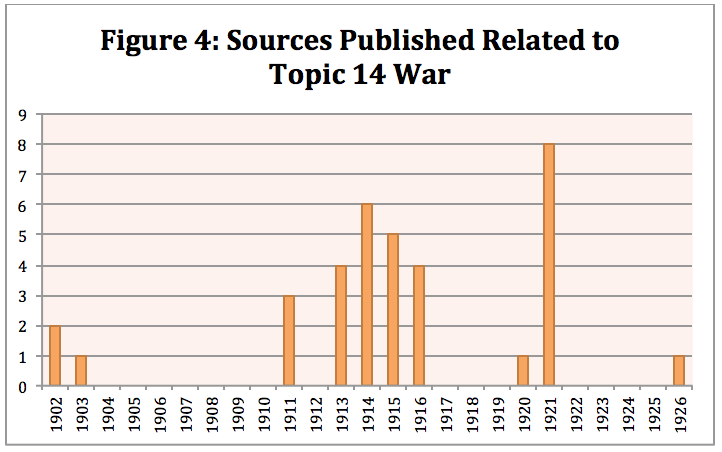
I also looked at the sources that listed war as the highest proportion in relation to eugenics. Figure 4 demonstrates that the eugenics movement was not consistently connected to war. The period between 1911 and 1916 makes sense as the world became preoccupied with the tensions in Europe just before the First World War and during the Great War itself, which meant it often permeated every aspect of life including eugenic ideas. The spike of publications in 1921 is the puzzling statistic. Perhaps it is due to the fact that it took a few years to understand the impacts that the war had on society and its people. I have two questions in relation to the war connection to eugenics in 1921. First, is war being discussed as a motivation to promote population growth through higher birth rates in order to make up for the population loss during the war? And second, is there a connection between eugenics and the number of soldiers that returned home from war as ‘unfit’ either mentally or physically? If I were to research further I would read the sources associated with the topic of war to see if I can answer these questions.
Figure 4
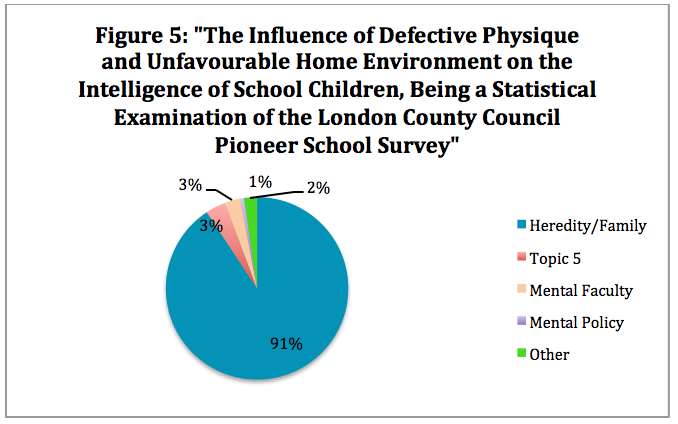
After looking at the corpus more broadly by year and topic, I decided to look at a few of the documents as a single source to see how an individual publication could also be broken down by topic. Some sources such as Figure 5 “The Influence of Defective Physique and Unfavourable Home Environment on the Intelligence of School Children, Being a Statistical Examination of the London County Council Pioneer School Survey” published in 1910, demonstrate that there was a very clear idea of what the author felt was most important. In this case, the study was concerned with the factors that most impacted a child’s intelligence[1]. The author identified home environment, family and the inheritance of ‘undesirable’ traits as the biggest influences in a child’s stunted intelligence. The chart also lists topic 5 as one of the larger factors, which was a limitation in my research since that was one of the categories I was unable to label.
Figure 5
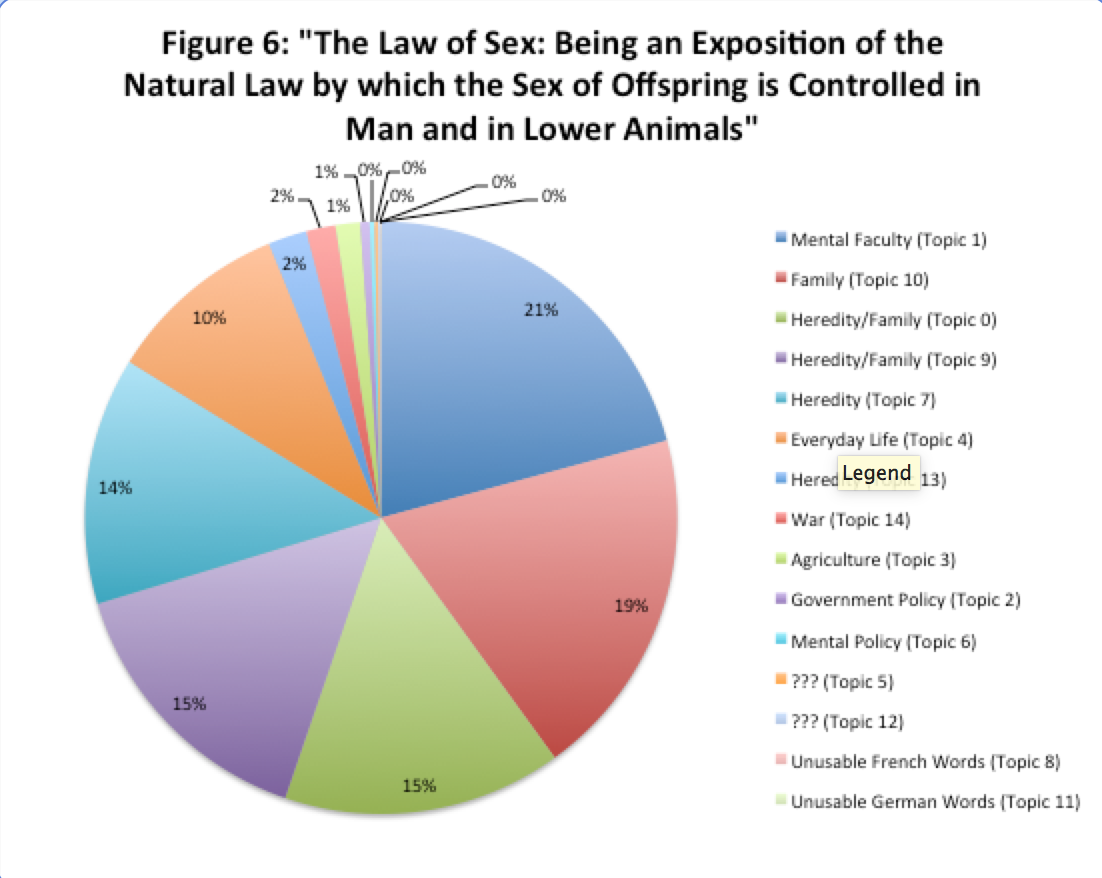
Other sources were slightly less decisive on which topic was most important. Figure 6 displays that the source “The Law of Sex: Being an Exposition of the Natural Law by which the Sex of Offspring is Controlled in Man and in Lower Animals,” which published in 1883, was a lot more fractured on what ideas were included in the text and encompassed six topics with fairly equal weight.[6]
Figure 6
My findings have only scratched the surface of the data that I generated. The dataset could in the future be further explored to include some of the other topics, such as everyday life, which also had a fairly high number of publications. The data could also be explored to determine how likely different topics were to be listed together based on the proportions.
[1] Alexander Walker, “Intermarriage: Or, The Mode In Which, And The Causes Why Beauty, Health, And Intellect, Result From Certain Unions, And Deformity, Disease, And Insanity, From Others”, Internet Archive, 1839, https://archive.org/details/intermarriageor00walkgoog.
[6] George Briggs Starkweather, “The Law Of Sex : Being An Exposition Of The Natural Law By Which The Sex Of Offspring Is Controlled In Man And The Lower Animals, And Giving The Solution Of Various Social Problems”, Internet Archive, 1883, https://archive.org/details/lawofsexbeingexp00staruoft.
In choosing text mining for my digital project I knew that I would have a few hurdles to tackle given the fact that I had never heard of text mining before this class. However, I never would have imagined that I would run into the number of issues that I did. Googling blog posts related to the programs eventually solved most of the issues, but it did take up valuable time that I wish could have spent on the actual project.
The first problem that I came across involved the corpus that I had chosen. My initial corpus of documents was actually from Jstor Data for Research and included 987 documents based on a preliminary search of population studies and the key term ‘birth’ from 1833 to 1925. My plan to use the corpus was derailed when I realized that the data generated by Jstor for all 987 documents was in the CSV format and MALLET required the .txt format. From there I had two options: I could attempt to learn python to create a code that would change the format or I could choose a new corpus. Not knowing how long it might take me to learn and create a python code, I opted for the second alternative and found my new corpus on the Internet Archive. Ultimately, changing corpuses was not a major setback but I did have to change my questions given the fact that I was now focusing on eugenics and not population and birth, and the number of documents that I actually looked at was cut in half.
The second problem that I had was downloading the Wget tool that I needed to use in order to download my corpus into MALLET. Using the programming historian lesson on Wget I learned that I needed to install a program called Homebrew, which would install Wget for me. The problem was that the operating system on my computer was out of date so I had to update my computer to the newest IOS, download a tool called Xcode, which then downloaded Homebrew, which finally downloaded Wget! From there I was able to use Wget to download my corpus into a single file in MALLET.
After running all of the installations, generating my 15 topics in MALLET, and outputting my composition file, I ran into my final problem. I realized that when I had initially retrieved the data from the Internet Archive I had not included ‘date’ as a field I wanted! My options at this point included re-downloading the data from Internet Archive with the date and year columns and restarting the entire process of using Homebrew, Wget, and MALLET to create a new composition, or I could attempt to match the documents in my current composition excel file with a new excel sheet that included the date and year. I decided to do the latter and after a few hours of matching the two documents, I finally had a single file that I could use to track change over time!
Despite all of the issues that I ran into, I believe that this project has really improved my skill and knowledge of digital methods and I would feel comfortable using the method of text mining in future projects.
I chose to use text mining to explore the topic of eugenics in the nineteenth and twentieth centuries. In the mid-nineteenth century, prominent figures in upper-class societies became concerned with the world’s population, more specifically the population of degenerate factions. The movement known as eugenics emerged in 1883 based on the activities of Francis Galton.[1]The study of eugenics, which means well-born, sought to examine the members of a society mentally and physically for ways to improve or impair the racial qualities of that societies future generations.[2]I used text mining methods including MALLET and Word Clouds to explore the relationship between the eugenics movement and which aspects of society those eugenicists were most concerned with.
Using the Internet Archive as my baseline, I did an advanced search using the keyword ‘eugenics’ and a date range of 1800 to 1945. I then further narrowed my search by changing the media type to only texts and choosing English as the language. Using these search parameters I was able to generate 465 documents pertaining to eugenics. I chose this corpus because it was large enough to constitute using the method of text mining while still being manageable enough for a third-year class project.
When I began this process my goal was to try to determine the patterns surrounding eugenics, especially which ideas were most common. I also sought to track how that might have changed over time.
Taking into account the goals of my project, I began by learning how to use the digital tool MALLET. Once I finished the programming historian lessons and felt proficiently able to confront my own project, I went to the Internet Archive website and attempted to start the download process. I quickly learned that it was not just a simple ‘download’ button. I needed to use the digital tool known as Wget. This was needed to transfer all of the files into a single directory on my laptop. Using the Wget code below, I was able to get all of my documents from the Internet Archive.
The corpus, which was comprised of a total of 465 .txt files, were each placed into their own folder on my laptop. And since text mining and MALLET require that all the files be in one directory, not separate folders, I first had to select all of the .txt files relevant to my project and copy them into a single folder.
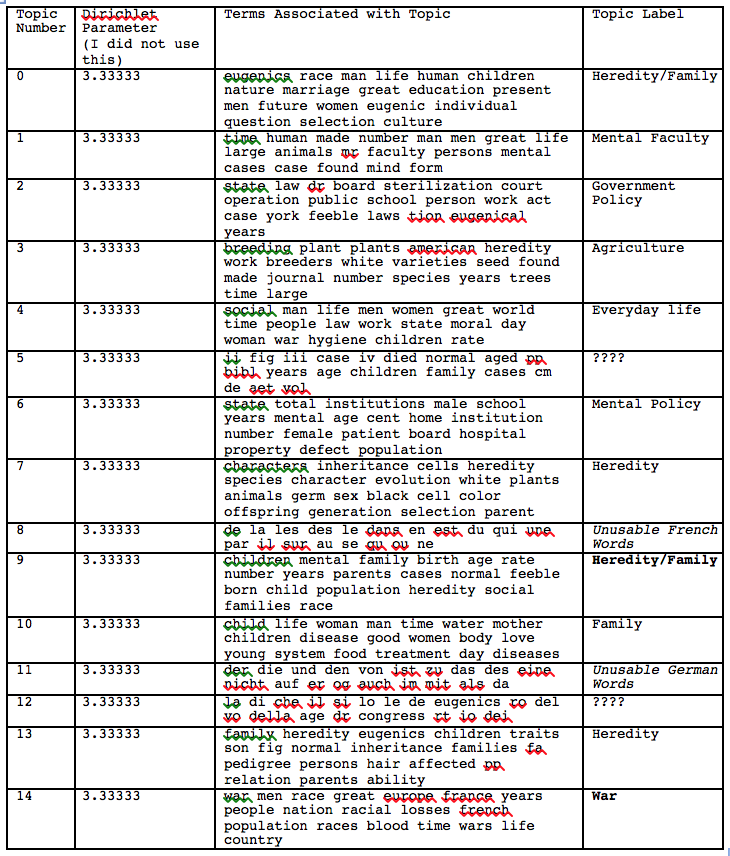
After that, I was finally able to begin the text mining process by importing the corpus into MALLET, and removing the stop words (and, the, but, etc.). Then using the .mallet file that I created when I imported my corpus, I was able to generate 15 topics most associated with eugenics and create an excel spreadsheet of the compositions of each document and what percentage they related to each topic. Table 1 below consists of the list of topics that were generated using MALLET.
Table 1: Topics Generated Using MALLET
Considering the definition of eugenics, I was most interested in the categories on heredity and how that impacted families. That is why for my project I have mostly focused on topics 0 and 9. I was also interested in topic 14 just to give a comparison of what other factors impacted how eugenics was written about in the nineteenth and twentieth centuries.
[1] Angus McLaren, Our Own Master Race: Eugenics in Canada, 1885-1945 (Toronto: University of Toronto Press, 2014), 15.